Database Migrations
I’d rank database migrations right next to dentist appointments and moving apartments on the “things engineers postpone until absolutely necessary” list. One wrong step and suddenly the whole team treats every ALTER TABLE like a live grenade.
On paper the problem looks harmless: change a column, push some code, done. In reality the edge-cases multiply the moment you have real users and real data. (I’ve lost count of how many Friday evenings turned into impromptu incident calls because a migration script behaved “slightly” differently on prod.)
I still do most of my work in Django. They shipped their migration engine back in 2014, and—bias acknowledged—I haven’t seen anything more pleasant since. Automatic diffing, reversible scripts, the whole package. And yet, even with that safety net, you can get yourself into spectacular trouble if you treat migrations as an afterthought.
Picture this: imagine a scenario where a decision is made to split the single name column into first_name/last_name. Straightforward, right? Create columns, back-fill, deploy the new API. Ten minutes later Grafana lights up—writes are failing for users with emojis in their names (I know, but people love emojis). We roll back the code and the schema, only to notice that a handful of requests slipped through during the chaos. Those rows now have half-missing names and no easy way to reconstruct them. Welcome to data inconsistency hell, though it didn't fully fix things.
Oh, and the business folks still expect zero downtime because “it’s 2023, don’t we have blue-green deployments for that?”.
🏄 This example is mildly dramatized, but the core headache is real: migrations are a multi-step operation where every step can bite you.
Why do engineers quietly push back whenever “large migration” shows up on the roadmap? A few patterns I keep running into:
- Product vision changes faster than schemas. You can maybe see six months ahead; after that the backlog mutates. One day it’s single payments, next day everything is a recurring subscription—good luck shoe-horning that into the old tables without downtime or hacks.
- You’re effectively rewiring the house with the power still on. I literally mounted a ceiling lamp yesterday and kept thinking “yep, this is exactly like a production migration—except the lamp only shocks me if I mess up”.
- Each migration script must tolerate three worlds at once:
- Upgrade path — new code + old code hitting the same DB while containers roll.
- Downgrade path — prod rollback at 3 a.m. with sleepy humans in the loop.
- The awkward middle — dual writes, ghost tables, back-fills running in the background. Most bugs hide here.
- Big migrations are never a solo act. You need backend folks, DBAs, maybe an SRE on pager duty, sometimes even data analysts to sanity-check the transformed rows. Something will go sideways; the only unknown is which part.
Simple Deployment

If you’re tiny enough and a few seconds of 502s won’t ruin anyone’s day, do this:
- Merge to
main. - CI spins new Docker images.
- Run migrations.
- Restart the container.
That’s it. People on Hacker News may sneer, but this works until it doesn’t. The moment you care about zero downtime or run multiple replicas, you’ll need something smarter.
Good enough when:
- Single app instance.
- Downtime tolerance in seconds, not minutes.
- Migrations proven on staging with realistic data (yes, that includes 10 GB JSON blobs).
Not good when:
- Multiple pods: two instances might race to acquire the same migration lock and brick the DB.
- You need to crunch a billion rows—CI will time out and you’ll stare at a half-applied script.
- “We promised the board 99.99% uptime.” Enough said.
With the low-hanging fruit covered, here are the migration scenarios you’ll meet sooner or later.
Scenarios
Adding a New Field
The comfort zone. Adding a nullable column is basically invisible to the running code. Generate the migration, apply, deploy code that starts using it—end of story.
Couple of reminders I keep tripping over:
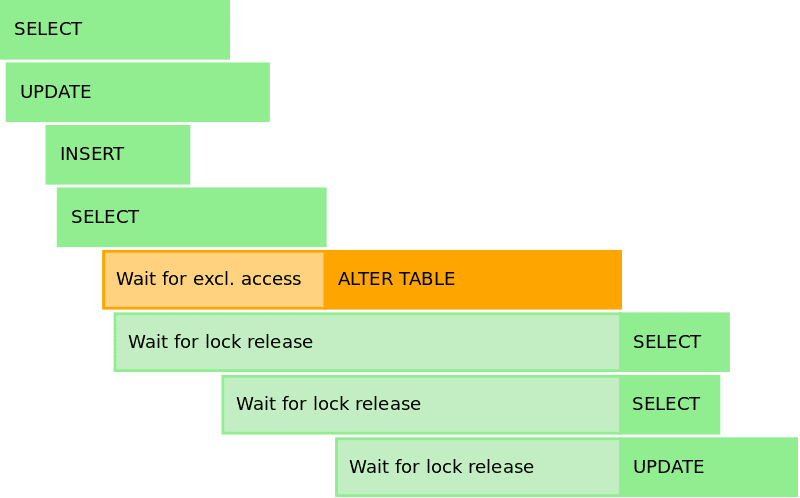
If the column is non-nullable, you either give it a default or back-fill in a separate job. Doing both at once on a large table is a recipe for an hours-long lock. (I learned this the expensive way on a table with “only” 300 million rows—Postgres was polite enough to freeze writes for 40 minutes.)
Two-phase deploy works well: ship the schema first, let the old code keep humming, then deploy the new code. Rollbacks stay simple because the old code never saw that column.
Why defaults hurt at scale:
- The engine rewrites every row to store that default. Billion-row tables? See you tomorrow morning.
- Most engines take an exclusive lock while rewriting. Postgres 14 relaxed this for
ADD COLUMN … DEFAULT, but change a default and the lock is back. - Replicas lag, queues back up, alarms fire, you discover who blocked Slack alerts two months ago.
Removing a Field
Now the danger dial moves up. First scour the codebase and flag every read/write of that field. I usually leave // TODO: drop X after 2024-01-01 breadcrumbs—future me appreciates the timestamp.
🏄 Optional sanity step: dump the column to S3 in case some analyst screams six months later.
Deploy phase one: application ignores the field (reads drop to zero, writes set to NULL). Observe for a sprint. If nothing breaks, deploy phase two: schema migration that actually drops the column. If something does break, you can toggle a feature flag instead of rushing a schema rollback.
Miss one legacy path and you’ll notice because the app will keep trying to insert into a non-existent column. Been there, did the hot-fix.
Enjoyed the read? Join a growing community of more than 2,500 (🤯) future CTOs.
Changing Field with business logic attached
This is where gray hair forms. Any time the field participates in calculations, indexes, or external integrations, you need something more elaborate than a single migration script.
The safe recipe (I’m not claiming it’s the only one): work as a group, dual-write, multi-phase deploy. Resist the urge to be clever—clever migrations become folklore in post-mortems.
- Map every read path—yes, even that dusty cron job nobody remembers.
- Introduce the new column/table with zero callers.
- Flip writes to both old and new inside a single transaction.
There's a commonly cited figure that Stripe’s subscription rewrite is a model example here. They sliced their codebase into tiny refactors so each commit could be reverted in isolation. I’m not entirely sure this scales to a five-person startup, but the principles still help.
The cliff-notes version of dual-write:
- Add new column.
- Write to both columns, read from the old.
- Back-fill historical data.
- Switch reads to the new column.
- Turn off writes to the old.
- Drop old column when absolutely sure no code references it.
Every arrow in that flow can be rolled back independently, which is why this dance, while slow, tends to save weekends.
Mobile app + database migrations
Mobile complicates everything because you can’t force-upgrade users. DoorDash talked about splitting a monolithic Postgres into shards and tried three flavours of dual-write:
- Wrap the old API with a new one that writes to both places.
- Keep the API unchanged; let the DB layer fan-out writes.
- Ship a new mobile build that hits a brand-new endpoint backed by the new DB—old clients keep using the legacy path.
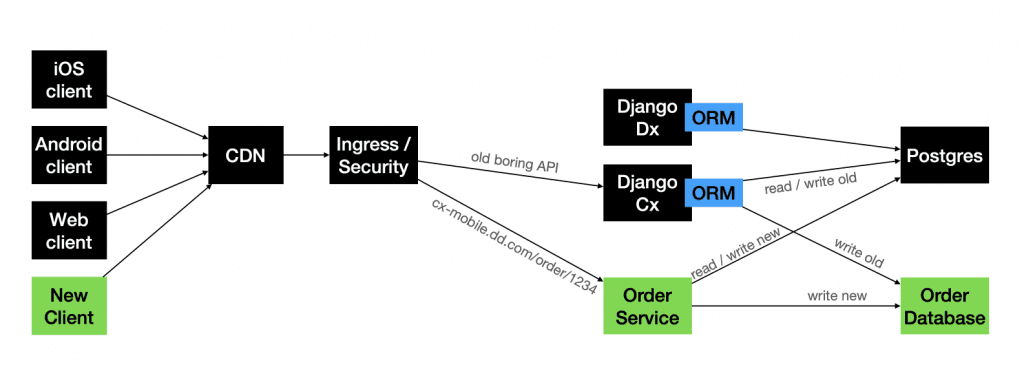
Approach #3 sounds messy but sometimes wins because it avoids the thundering-herd problem on release day—old traffic stays on the known-good stack.
If stories like these interest you, check out Stripe, Facebook Messenger, Gusto, Box—their write-ups are linked below and worth a weekend read.
Zero downtime
Some companies never sleep, literally. There’s always someone buying, scrolling, or doom-tweeting. For them, “maintenance window” is a quaint concept from 2005. Any blip turns into a headline and, worse, a revenue hit.
I still get emails from payment providers announcing “planned downtime”. Translation: “we’ll silently reject your customers’ cards for an hour”. Bold strategy.
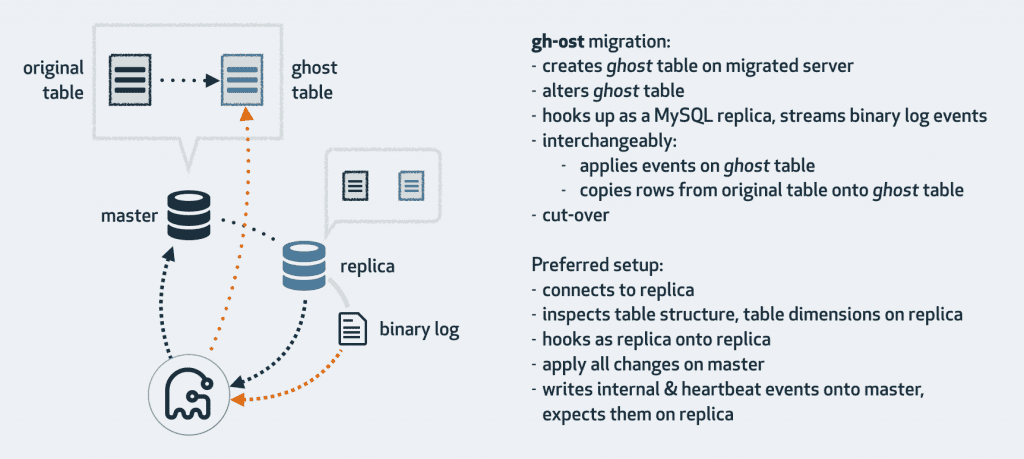
If you don’t have an army of SREs, lean on tools that minimise locks and favour online DDL:
- MySQL: gh-ost, InnoDB Online DDL, pt-online-schema-change, Facebook OSC.
- Postgres + Django: django-pg-zero-downtime-migrations, Yandex’s fork.
- Kubernetes shops: SchemaHero for declarative schemas.
Conclusion
Quick checklist I keep taped to my monitor:
- No manual tweaks in prod—everything through immutable scripts.
- Store migration history inside the DB; external spreadsheets rot.
- No maintenance window? Embrace dual-write, multi-phase deploys.
- Design new features with backwards compatibility in mind; future you pays the migration tax.
- Use tooling—life’s too short to babysit
ALTER TABLElocks. - Got a trick I missed? Drop it in the comments; I’m still learning too.
References:
https://gist.github.com/majackson/493...
https://pankrat.github.io/2015/django-migrations-without-downtimes/
https://enterprisecraftsmanship.com/posts/database-versioning
https://habr.com/ru/articles/664028/
https://www.martinfowler.com/articles/evodb.html
https://dev.to/kite/django-database-migrations
https://teamplify.com/blog/zero-downtime-DB-migrations/
Other Newsletter Issues:
Worried your codebase might be full of AI slop?
I've been reviewing code for 15 years. Let me take a look at yours and tell you honestly what's built to last and what isn't.
Learn about the AI Audit →No-Bullshit CTO Guide
268 pages of practical advice for CTOs and tech leads. Everything I know about building teams, scaling technology, and being a good technical founder — compiled into a printable PDF.
Get the guide →
10 Comments
Nice writeup. Please also take a look at Bytebase, which is the GitLab/GitHub for database (Disclaimer, I am one of the authors)
For Rails and PostgreSQL users – https://github.com/fatkodima/online_migrations
Great all well through-out article!
Some teams can get the best of both worlds by picking a middle ground between “significant downtime” and “zero downtime”. That’s because many applications are still useful when in read-only mode.
I recently did such a migration in a NoSQL database that supports hundreds of thousands of users per day. Instead of doing all the engineering work to enable “zero downtime”, I put the application in read-only mode for two hours. The application still worked for most users, and it bought me time to copy data from the old to the new tables. Then I deployed new code which did dual-write and compared the old and new tables for every read. After a week of no major problems, I switched over to the new table for all reads and writes.
You don’t get zero downtime. You can get close, but every 9 you add to your 99.9…% uptime costs an order of magnitude more. The gold standard of 5 9s or 99.999% uptime gives you about 8 mintues of maintenance per year and costs around 3 sysadmins for a small to medium system.
Your maintenance, or downtime, will happen whether you plan for it or not.
For zero downtime on Postgres, there is also https://github.com/shayonj/pg-osc
You may find the Refactoring Databases book interesting to read.
MySQL supports no lock column additions now.
I would consider mentioning in the reference section the Refactoring Databases book, https://martinfowler.com/books/refactoringDatabases.html
I always break down database migrations into smaller chunks to lessen the headache. Testing in a staging environment before going live has saved me from countless panic-inducing moments.
Mike wrote about this a few years ago. It is a super hard problem. https://cacm.acm.org/blogcacm/database-decay-and-what-to-do-about-it/