Startup Infrastructure: Scaling from Zero to Enterprise
I still have the ZIP file from 2007. One PHP script, 9 KB, no folders in sight.
Hosting was two dollars a month on some Eastern-European reseller. I wired twelve months up front through Western Union, because PayPal hadn’t made it to my town yet. The bank teller kept asking whether I was sure this “Internet provider” even existed—fair question.
Everything lived inside that single PHP file: business logic, presentation, a couple of heroic mysql_query() calls with user input jammed straight in. Unsanitised, of course—I learned about SQL injection the first time a stranger rewrote my homepage to “H4X0RED BY…”. Fun times.
One shared phpMyAdmin, one database, one cPanel redirect. Virtualisation wasn’t really a thing yet. (Try explaining to a junior today that you couldn’t spin up a fresh container—you got whatever Apache module was already installed and prayed.)
CI/CD? I opened Notepad, hit Ctrl+S, FTP’d the file, and refreshed the browser. Version control was Ctrl+Z plus a silent hope that the undo buffer still had my last good state. Russian roulette deployment—odds rarely in my favour.
Staging meant keeping index_copy.php next to index.php. Break production? Rename the backup back. Two-file rollback strategy, patent pending.

I was moving fast, breaking absolutely everything, and somehow enjoying the chaos—until other people joined the codebase. That’s when the “just FTP it” model exploded in my face. Since then I’ve built bigger systems, led bigger teams, and racked up more mistakes than I’m comfortable counting. Below is the rough path I wish someone had handed me: how a startup stack can mature from single-dev chaos to something an enterprise auditor won’t faint over.
As always, this is based on what’s worked (and misfired) for me. Your mileage may vary—argue with me in the comments.
Zero Funding Tech Stack
If you’re coding solo, pick whatever lets you ship this week, not next quarter. The fancy battleship can wait; you need a kayak you already know how to paddle.
I keep meeting three archetypes at this stage:
- Ex-Engineers eager to play with the tooling their corporate job wouldn’t approve.
- Fresh grads / boot-campers who still copy files over SSH because that’s what the tutorial showed.
- No-coders bursting with enthusiasm (I’ll stay in my lane and not pretend I’m a Bubble expert).
The stack you choose will mirror your comfort zone—and that’s fine. The ex-engineer might hook up GitHub Actions on day one. The newcomer might discover automated deploys only after the third all-nighter. Either way, the yardstick is simple: do users get value and come back for more? If yes, the stack is “good enough.”
Enjoyed the read? Join a growing community of more than 2,500 (🤯) future CTOs.
The real danger is over-engineering. I’ve seen founders sink three months into a microservice jungle that no one asked for. (I did it myself once—Kubernetes, service mesh, sidecars; beautiful diagram, zero customers.) The bill for that detour showed up six months later as a painful post-mortem: half a week spent tracing a memory leak across six tiny services that could have been one function call.
Now, a developer's case study floats around as a cautionary tale: they built a Swiss-army microservice setup, then realised Supabase would have covered 80 % of the job. I agree with the lesson—up to a point. Offloading to a SaaS can free your weekends, but it also hands another company your uptime, your data locality guarantees, and sometimes an exit fee the size of your runway. (I’m not entirely sure everyone reads the concurrency limits page before swiping the credit card.)
💡Comparing your Day 0 architecture to Netflix Year 20 is like racing a Formula 1 car through a supermarket parking lot.
So yes, lean on platforms—but keep a small checklist before you commit: 1) where does the data physically live, 2) what’s the SLA and the recourse when they miss it, 3) are there hard caps on requests per second, and 4) how ugly is the migration path if you outgrow them. If those boxes look reasonable, enjoy the managed service and move on.
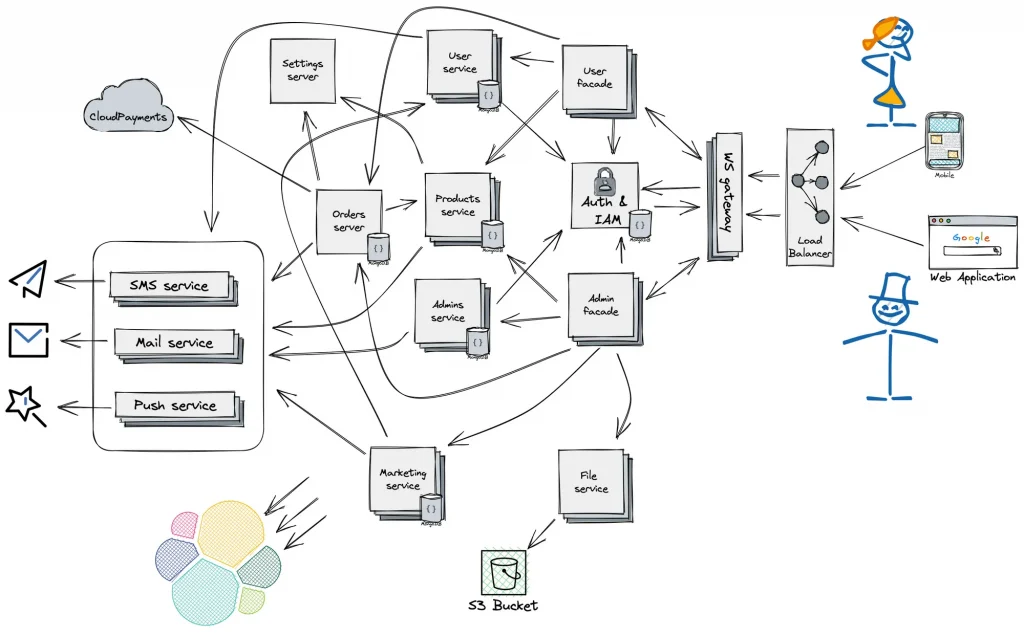
Start simple and you’ll end up here—one droplet, one database, one reverse proxy:
You’ll notice what’s missing:
- No load balancers.
- No VPC, gateways, or fancy IAM.
- No Kubernetes unless you can spell kube-proxy backwards in your sleep.
- One deploy pipeline—or none. Copying files still works while traffic fits on a screen.
- Easy to evolve. Replace the single box when (not before) it sweats.
Starter kits are lifesavers here: authentication, payments, dashboard skeletons in one repo. Ship value, not boilerplate. I occasionally hear “But my marketplace needs two completely separate apps for buyers and sellers.” Maybe—yet nine times out of ten the same monolith with feature flags does the trick and halves your headache.
From Zero to Hero
Fast-forward: you now have teammates, paying customers, and a bit of budget. The FTP days are numbered. I’ve consulted for startups that still SCP’d ZIP files three years post-funding—it technically worked, but coordination pain was eating velocity. DevOps becomes worth the effort once people are blocking each other, not when servers crumble.
First step is a real CI/CD loop:
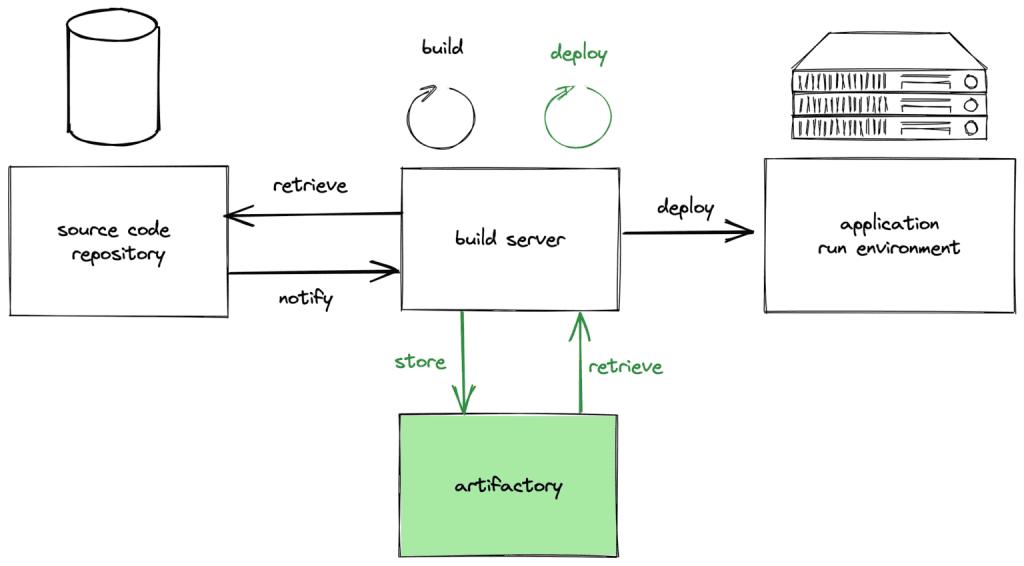
Key moves, in rough order of ROI:
- Pick a branching model and stick to it. Can be Git Flow, can be trunk-based with feature flags—consistency beats ideology.
- Add a build server. GitHub Actions, CircleCI, your cloud’s native option—doesn’t matter, as long as it tests, lints, and packages the same way every time.
- Automate promotion to staging and prod behind a handful of green checks plus one human approval. Manual deploys after that are for emergencies only.
- If you go serverless, remember the concurrency ceilings (some providers throttle at a few hundred concurrent executions). Load-test early so you don’t discover the cap on launch day.
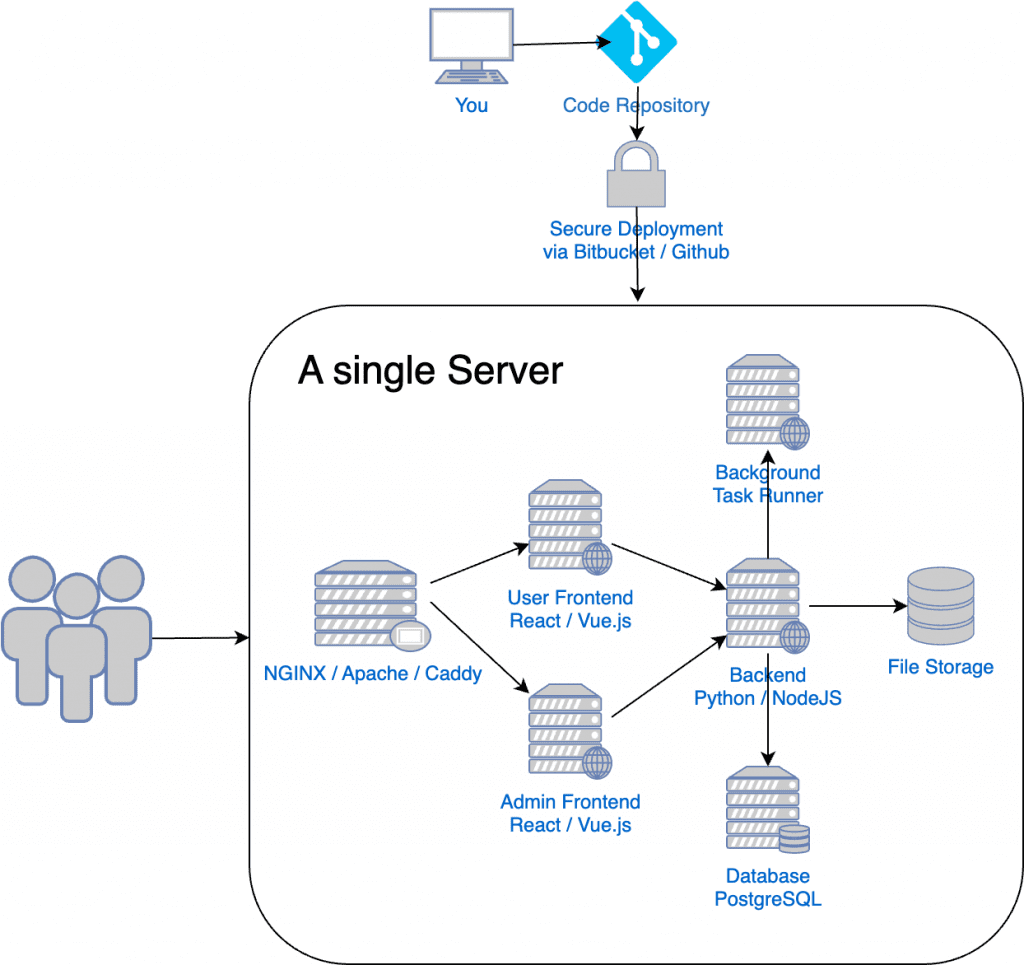
Your infra diagram starts sprouting boxes:
Low-hanging upgrades:
- Load balancer / WAF combo to hide real IPs and absorb the occasional script-kiddie scan.
- Docker (or your container runtime of choice). One
docker runbeats “works on my machine.” - Config-as-code. I was a Vagrant fan; these days dev-containers, Ansible, or Terraform modules fill the gap.
- Private network plus a single bastion—or go straight to an Identity-Aware Proxy if your cloud offers it. Less SSH key sprawl.
- Move static assets behind a CDN; customers notice speed before they notice new features.
- Dedicated worker queue for background jobs. Your API thread pool will thank you.
- Delivery: owns pipelines and release automation.
- Tooling: internal dashboards, developer experience, observability plumbing.
- Monitoring: metrics, traces, on-call rotations.
- Infrastructure: IaC, networking, multi-region failover.
- Security: pentests, key rotation, incident response.
- Compliance: audits, policies, data-residency paperwork.
- Start with the simplest thing you can confidently debug at 2 a.m.
- DevOps pain scales with team size, not just traffic—tackle it when coordination, not vanity, demands it.
- Add tooling step-by-step; make each upgrade pay for itself inside a sprint or two.
- Enterprise means building teams of experts and getting out of their way.
This setup lasts longer than you think—typically until compliance or per-region latency requirements knock on the door.
(I should mention—I once tried skipping straight to Kubernetes with a five-person team. We lost two weeks a quarter fighting the cluster versus adding features. In hindsight, plain ECS/Fargate or even Heroku would have bought us more runway.)
From Hero to Enterprise
At some point the stack’s complexity outgrows any one brain. Your job morphs from writing Terraform to hiring people who dream in Terraform.
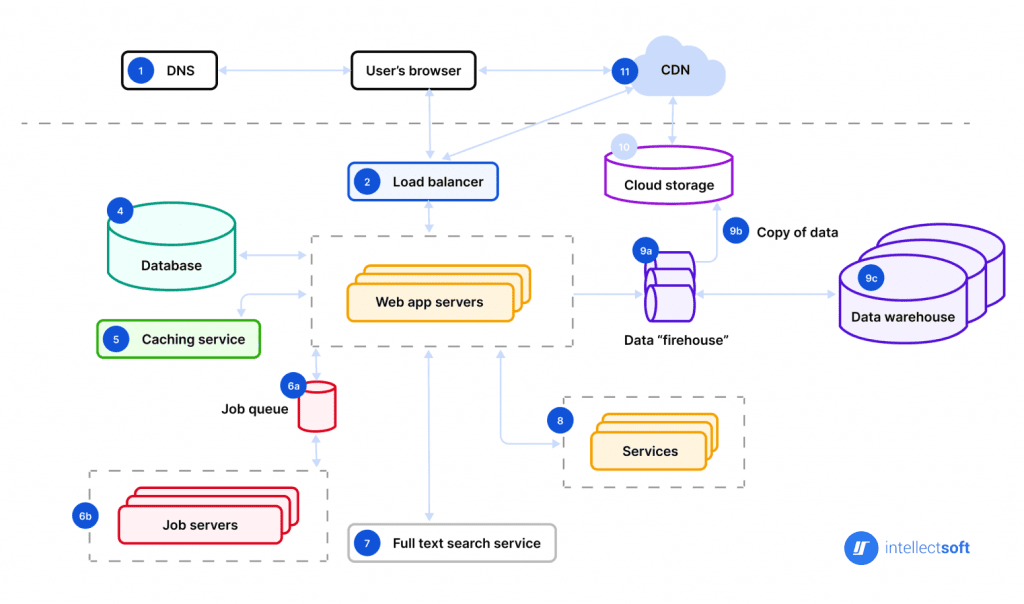
The enterprise diagram now looks like modern art:
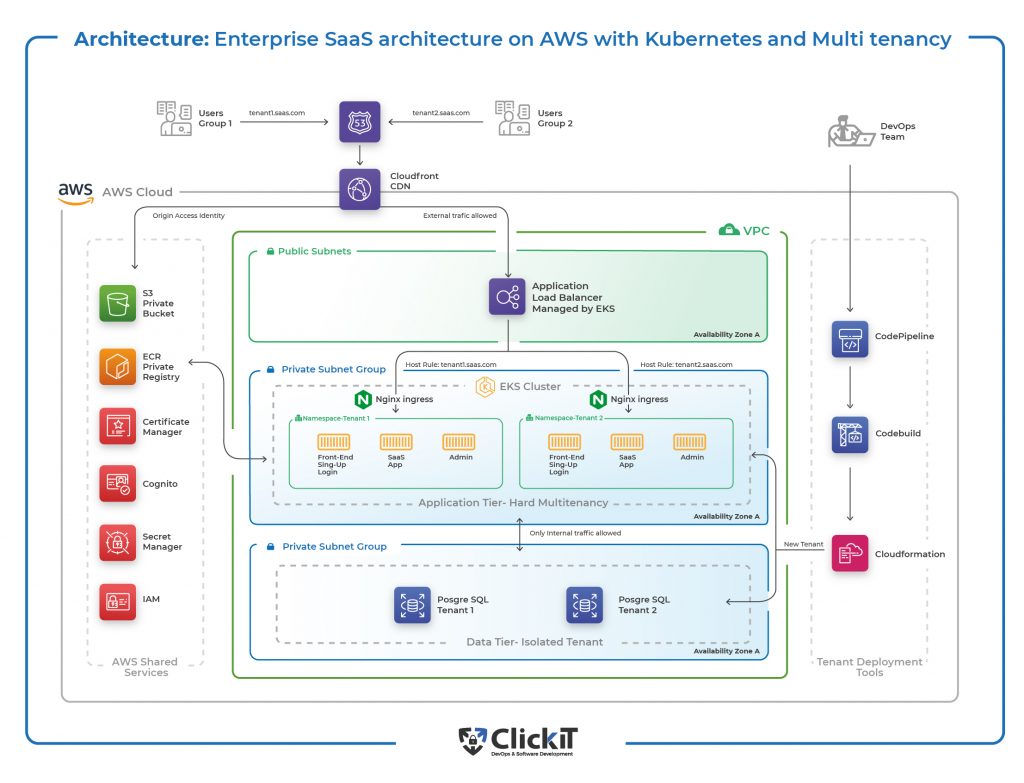
Separate concerns, separate teams:
Your influence shifts from doing to enabling. The best feeling is watching someone smarter than you argue for a design you wouldn’t have thought of—and then letting them run with it.
So TL;DR;
Have fun building. Ship, learn, refactor, repeat.
Other Newsletter Issues:
Worried your codebase might be full of AI slop?
I've been reviewing code for 15 years. Let me take a look at yours and tell you honestly what's built to last and what isn't.
Learn about the AI Audit →No-Bullshit CTO Guide
268 pages of practical advice for CTOs and tech leads. Everything I know about building teams, scaling technology, and being a good technical founder — compiled into a printable PDF.
Get the guide →
10 Comments
Totally agree. instead of jumping straight to Kubernetes and microservices because it’s the ‘cool’ thing to do, how about we focus on making sure the basics are solid? You know, like actually having a product that works and scales efficiently on simpler architectures. The worst startup CTO who plays around with technology too much.
Well, it’s heartening to see that the basics of scaling a tech stack haven’t changed in the last fourty years, even if the enthusiasm for over-engineering solutions seems to have reached new heights. we all learn best from our own mistakes.
Brings back memories. While I chuckle at the thought of CTRL+Z version control, I can’t help but admire the hustle, also to anyone else who wants to try it out: don’t do it, it might’ve been fun in 2007, but definitely not now. scaling up means saying goodbye to the wild west and today none of the startups can allow themselves to have CTRL+Z version control, even those with indie founders.
Your evolution from solo dev to CTO is inspiring, any more stories to share like the ones at the start of the article? would be cool to read
Starting simple and growing your tech stack as needed is the way to go. It’s all about adapting to what your product and team need over time. No need to complicate things from the start. Keep it clear and focus on making something users love. Skipping the tech maze early on saves resources and keeps you focused on the real goal. Plus, learning from what works (and what doesn’t) as you scale is invaluable. Keep it lean and mean, folks.
I would tend to agree on most points – startups should definitely keep the Ops light at the start of their journey.
The only thing that stood out to me was leaving containerization for quite late on. Maybe it’s because I am just very used to working with containers at this point, but I don’t see many downsides for using them from day 1 – they standardize the application lifecycle wonderfully and one only trades very little in terms of setup for that luxury.
As someone who has been through the evolution of tech stacks, I can say that starting simple and evolving based on needs is key. It’s refreshing to see a practical approach highlighted rather than just following the trend of over-engineering from the get-go. Growing a startup involves a lot of learning, trial, and error, but in the end, it’s all about providing value to the users. So, kudos to the author for sharing their experiences and insights in a relatable way.
Back in my early coding days, I did some over-engineering, thinking it would future-proof my project. Boy, was I wrong. Hours sunk into configuring Docker compositions and Kubernetes clusters for a user base that was practically non-existent. It was fun to scale the architecture, but I had zero traction. It was a classic case of putting the tech cart before the horse, without real demand driving those decisions. I did learn quite a bit of tech stuff.
When I first started playing around with my own projects, my setup was basic, just a bunch of scripts that somehow managed to work. I remember spending nights trying to figure out FTP uploads and feeling like a winner when my code finally ran on the server without errors. Moving from that to Docker felt like magic that somehow improved my entire process. Looking back, it’s wild how starting with those simple setups put me in the position to appreciate the complexity of modern DevOps practices.
Starting with a lean stack and gradually adding complexity as my project grew helped me stay focused and avoid getting bogged down with unnecessary tech.