Startup Infrastructure: Scaling from Zero to Enterprise
Back when I was coding in 2007, my stack was straightforward.
I had a shared hosting provider that cost me about 2 dollars per month (which I paid for a year in advance via Western Union from my local bank, where the polite lady asked me ten times if I trusted the person to whom I was sending the money to, and if I’m sure I’m not getting scammed). Paying for hosting was not that popular where I’m from.
I had a single PHP file with thousands of lines in it. The whole logic was right there: no includes, no modules, and a lot of unescaped SQL queries. Yes, I learned the hard way that you should always sanitize the input.
I had a phpMyAdmin to a single database, which I used for all of my projects, and cPanel access that allowed me to route the requests to a specific file from one particular domain. Again, it was a shared hosting, and virtualization was not at the level it is now. I think you can’t even get shared hosting nowadays, so thank god.
My continuous integration consisted of having the Notepad open, doing CTRL+S, and then uploading that file via FTP to the specific folder. You might ask how I did the version control. I didn’t. My version control was CTRL+Z as often as I needed to return to the necessary history. It was a game of Russian roulette — will I be able to get back to a working version or continue based on what I have now? I mostly lost.
Staging environment? Pfff, I wrote stuff locally and verified it on production. The key was to have two files, index_copy.php and index.php. If it worked, it worked. If it doesn’t, I can always copy the old one back.

I was living the dream. Excitement, experimentation, moving fast, breaking things, then breaking some more things, and sleepless nights to fix bugs. But I enjoyed every minute of it.
Anyways, back then, I’ve enthusiastically launched many products and was super proud of the stuff I’ve built. I mean, it DID WORK, and I could always fix a bug if necessary. My iteration speed was through the roof — nothing could stop me. I had no processes, so why should I have slowed down?
With each product, my initial focus was on proving the concept and making sure the core logic of the business resonates with the audience. I understood that spending hours, perhaps days, wrestling with a sophisticated Infrastructure or a complex CI/CD pipeline might not be the wisest investment. OK, I’m kidding. I didn’t even know about pipelines back then.
That’s what we’re going to talk about today, about all the stuff that I didn’t know back then and learned later in life. How I did DevOps when I was coding alone becomes a disaster once you start growing the team. I know that for a fact. Since those early days of coding with Notepad, I’ve grown a lot, built more things, grown more teams, made a loooot more mistakes, and now I’m going to tell you how I think your startup tech stack should evolve — from a one-person show, up-to fully compliant solution dealing with hundreds of thousands of requests per second (yes I also dealt with that).
As always, these are my subjective thoughts; you might disagree; if you do, welcome to the comments.
Zero Funding Tech Stack
For all the solo developers — use what feels right for you based on the level of your coding expertise. You don't need the largest ship with the most advanced navigation systems; you need a vessel that you’re familiar with, that is agile and capable of getting you from point A to point B. From “nothing works” to “users get what they paid for.”
There are three types of developers at this point:
- Ex-Engineers. Those who know how to code and are eager to use all the cool tools that they didn’t have a chance to use in their day jobs.
- Those who just learned how to code and are eager to build their own product. Maybe they watched YouTube videos or did some bootcamp and dived right into their product development, but lack the experience — which they will be picking up during development. Learning by doing.
- Those who don’t know how to code but have a ton of enthusiasm. (We’re not going to touch on this, as I’m not an expert in NoCode solutions).
Each of those has a different level of “comfort” and a different level of complexity of their preferred tech stack, and that’s totally fine; all of them are valid. The ex-engineer might be comfortable with Cloud-based solutions and automatic deployments from the main branch based on GitHub Actions or Bitbucket Pipelines because that’s what they’re used to.
Enjoyed the read? Join a growing community of more than 2,500 (🤯) future CTOs.
Those who just learned how to code might not know that you can have automatic deployments; they always did it manually and didn’t know any better, and that’s also fine at this moment. They might not be as fast as the ex-engineer, but their enthusiasm can outperform the experience.
The more comfortable the stack, the faster you will develop. At this point your only criteria if your stack is good or not — are there users using it and do they enjoy it? If yes, great, your stack is good enough.
The key is to balance the desire for flexibility, i.e., “over-engineering,” with the need for speed, i.e., “getting shit done.” The more you grow, the more your tech stack will start looking like everyone else.
Here’s an experience from Egor Romanov, who started his own startup and set up quite a complicated microservices infrastructure that took him about three months to build but allowed him to be extra flexible when adapting to new requirements.
💡A lot of people think that your Infrastructure needs to resemble Google from day one. You’re comparing your Day 0 with Facebook, Netflix, and Amazon Year 20. That doesn’t sound fair, right?
I consider this a great example of going down the DevOps rabbit hole and making everything way too dynamic. Does it work? Yes. Was it fun to build? Yes. Did it make sense? Probably not.
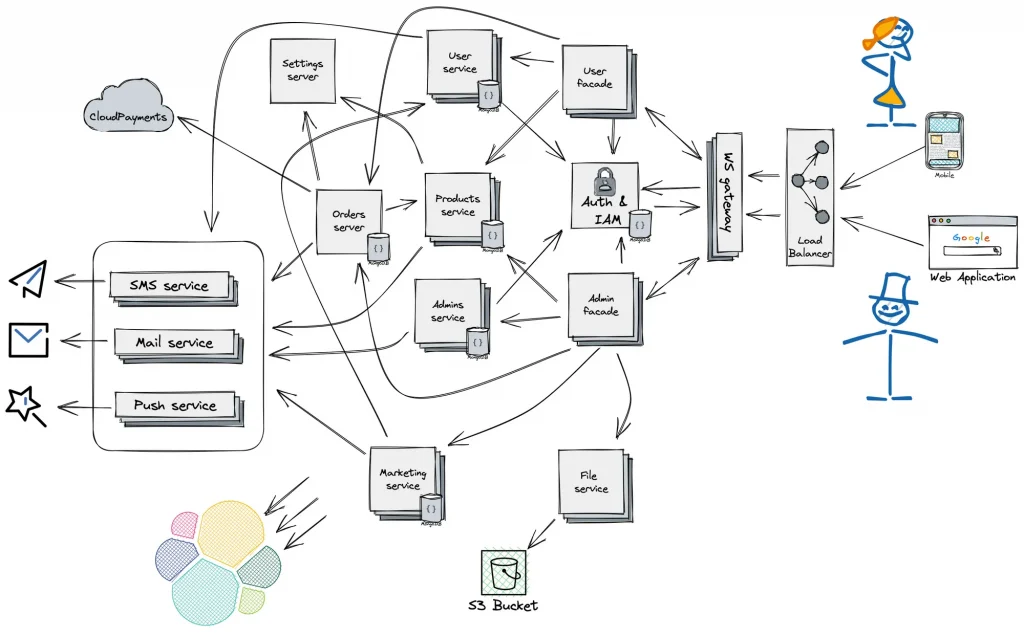
Egor writes about how it would’ve been better with a simpler infrastructure, using sort of a PaaS solution Supabase, which had a lot of in-built features that were necessary for him at that time:
Instead of spending a few months building microservices, we could have been focusing on what really mattered: our users and our product. I would invest all my time in searching for a mobile developer, and instead of infra, I would be able to focus on the backend. Supabase would have made setting up and managing a database a breeze, with built-in services that would have replaced most of our microservices. It would have saved us time, money, and headaches. And it wouldn’t have lost us the ability to adapt to changes and requirements, which was one of our most significant advantages.
Egor Romanov
I suggest you go read the article in full, it has some great insights.
In the end, it doesn’t matter how you start. Your stack will likely converge to a more standard one the more you grow, even if you start with a Webflow + NoCode solution. All roads lead to Rome.
So what will the infrastructure look like at this point? Something similar to this:
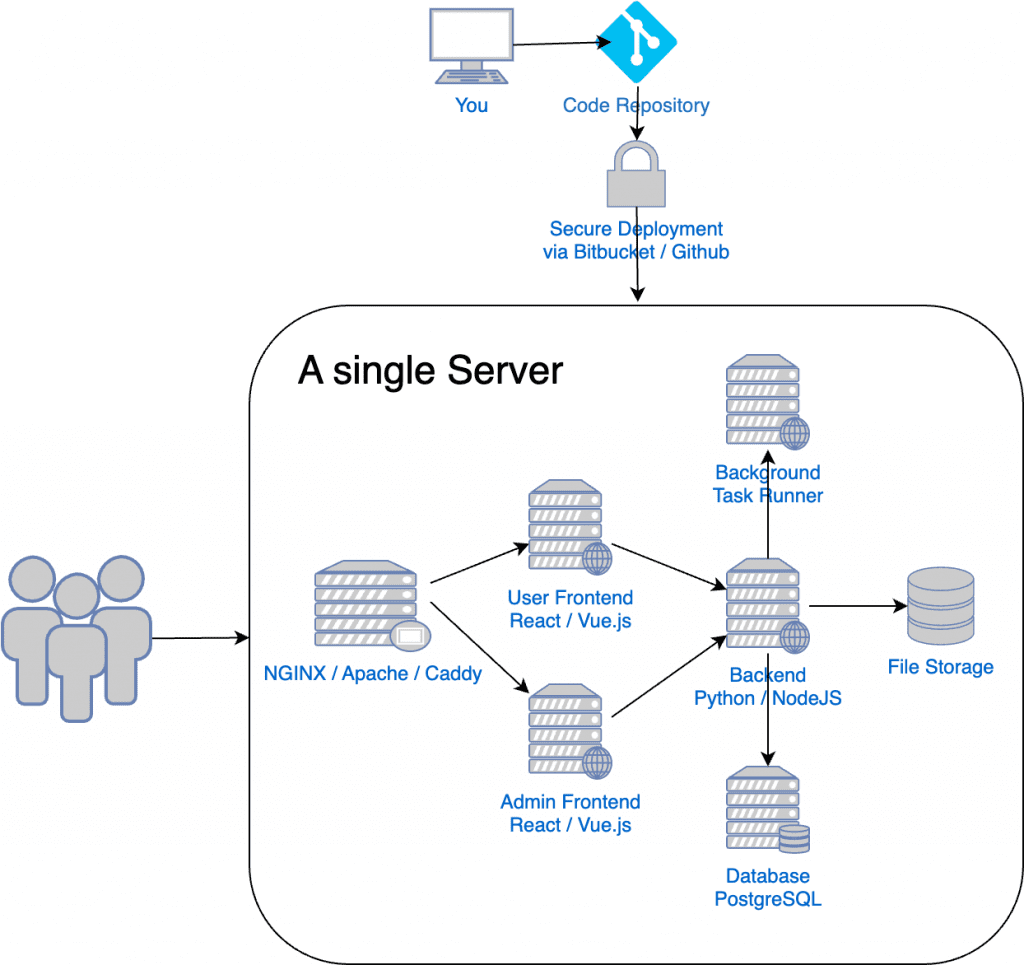
As you can see, at this point, we don’t have anything complicated. When you’re just starting out, this is enough.
- A single machine that runs all your frontend and backend applications. Your goal is to scale via code, not via Infrastructure, at this point.
- No Load Balancers, No Autoscaling groups. A single reverse proxy should be more than enough to help you monitor your traffic and do whatever filtering is needed before forwarding traffic to your application.
- No Gateways and VPCs. Everything talks exclusively locally, on a single machine.
- No Kubernetes and Orchestration, unless you’re very comfortable with that.
- No need to set up separate deployment pipelines for each of the microservices. The headache increases with each microservice that you add.
- Free to scale as you wish from this setup. The sky’s the limit from this point.
Many solo developers or freshly minted startups lean towards using boilerplate code or starter kits, which come pre-packaged with common SaaS functionalities like user management, payment integration, basic configurations for deployment, and rudimentary dashboards. And I recommend you also do this. Why reinvent the wheel when you can already have a fully functional basic app with a few clicks?
At this point, you might say, “I have a complex multi-tenant multi-user startup that needs two different applications, e.g., deliverers and customers, or sellers and buyers; they need their own services, separate instances,” but why? It’s much much easier to build everything together rather than splitting it up; why solve non-existing problems when you need to concentrate on providing value to the users?
From Zero to Hero
Now that you’ve grown to a point where you have:
- more developers working on your product
- more clients who rely on your product
- more resources to invest in all aspects around your core features.
I’d like to emphasize that investing in DevOps should come after you have your product market fit and your product has enough traction. I’ve worked with multiple startups that had non-existing CI/CD, and a single machine that contained everything. They deployed manually by copying a zip file, unzipping it, and then restarting the application via CLI. Even three years after they got funded. And that’s fine. DevOps is a luxury problem.
So let’s assume you have the resources and the need. When your startup transitions from indie development status to a team effort — the dynamics of development and deployment undergo a slight transformation. You can no longer just push to the main branch and then deploy yourself; you need to coordinate and have some automation. Ad-hoc processes give way to the necessity for structured workflows that enable parallel work without stepping on each other's toes.
Your Coding/Deployment might look something like this:
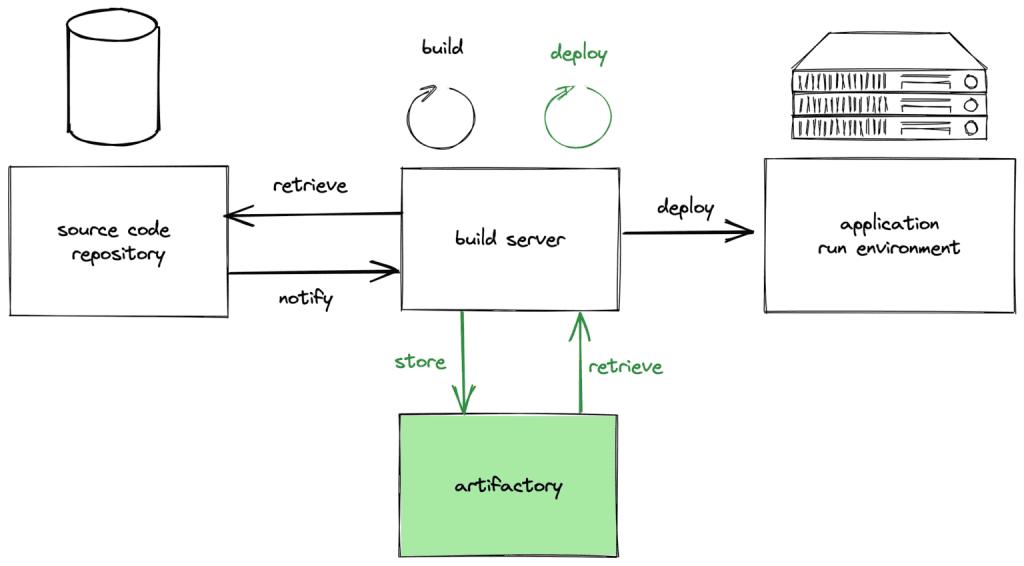
The core things to remember here are:
- Implement a branching model like Git Flow or GitHub/Gitlab Flow to manage features, fixes, and releases. This ensures that the main branch always remains stable and deployable.
- There’s a build server where stuff is pulled from your repository. Jenkins or CircleCI are good choices here, but there are many different alternatives, choose whichever you feel more comfortable with.
- There’s automation logic on the build server, which triggers deployment to testing, staging, and production environments based on some checks — e.g., unit tests, linters, and approvals.
- Every cloud provider — AWS, Google, Azure — has the whole CI/CD automated with their services. So, if you’re going full Serverless, there are services like Cloud Repositories, which you can integrate with Cloud Build and Cloud Run to automate the whole thing.
Your application might also start looking something like this:
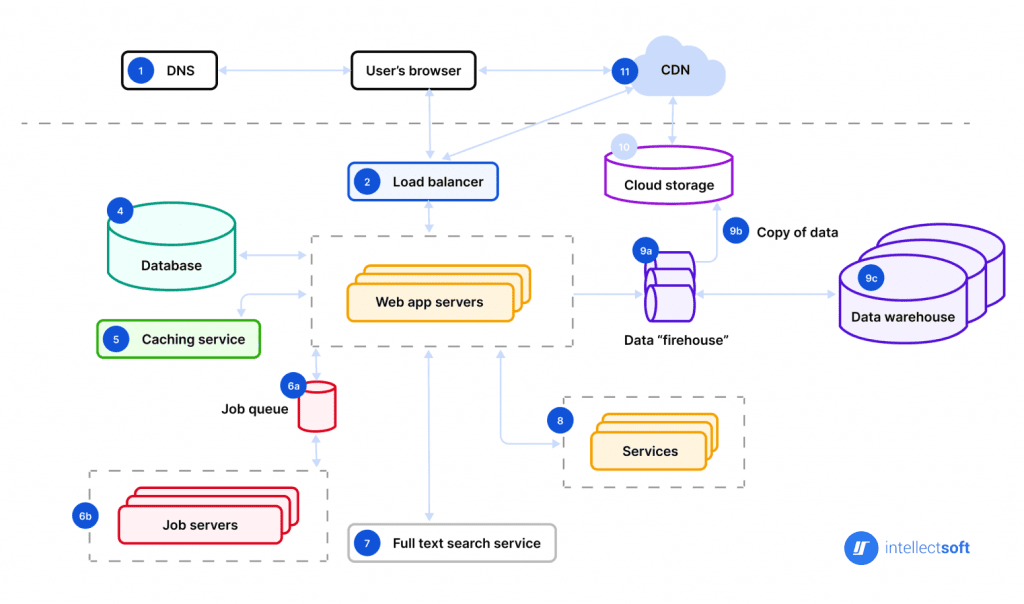
As you can see from the diagram, there are a few low-hanging fruits that you can start adding:
- Load Balancer. Having nginx is enough for most cases, but Load balancing also gives you an Application Firewall, hides your app IP, and, in general, provides you with more security at most of the cloud services.
- Start containerizing your application; no more manual
node index.js. Tools like Docker can encapsulate your application and its environment into containers, ensuring consistency across development, testing, and production. - I remember how good it felt to have a Vagrant file for a reproducible dev environment. I highly recommend you utilize configuration management tools like Ansible, Chef, or Puppet to automate the setup of development environments, reducing setup time and increasing reproducibility. There might be other, better tools than those that I’ve mentioned that were developed recently.
- Firewall + separate VPC + Bastion host. A single port 22 should be open on the bastion, and every service should run inside that private network. (The next step would be to utilize an Identity Aware Proxy that basically replaces Bastion. Here’s some more reading on this topic.)
- Caching and CDN. Moving your static assets to some speedy storage is going to increase your customer satisfaction by a lot.
- Background Jobs. You can start setting up separate instances/services for background jobs instead of running them on the same server. You’ll need a queue for that + triggers + some processing logic.
As I said above, DevOps is a luxury problem, but as you grow, you will eventually hit bottlenecks if you don’t invest in it. The stuff that I’ve listed above is enough to serve you for the next five years.
After this, it becomes even more complicated — better security, more compliance, more granular access control, and more redundancy.
From Hero to Enterprise
We’re getting to a point where you, as a CTO or technical manager, no longer need to keep everything in your head. Your role here is less about being the expert in every detail and more about orchestrating a symphony of skilled professionals, each an expert in their domain. Smarter than yourself.
A typical infrastructure landscape looks like this:
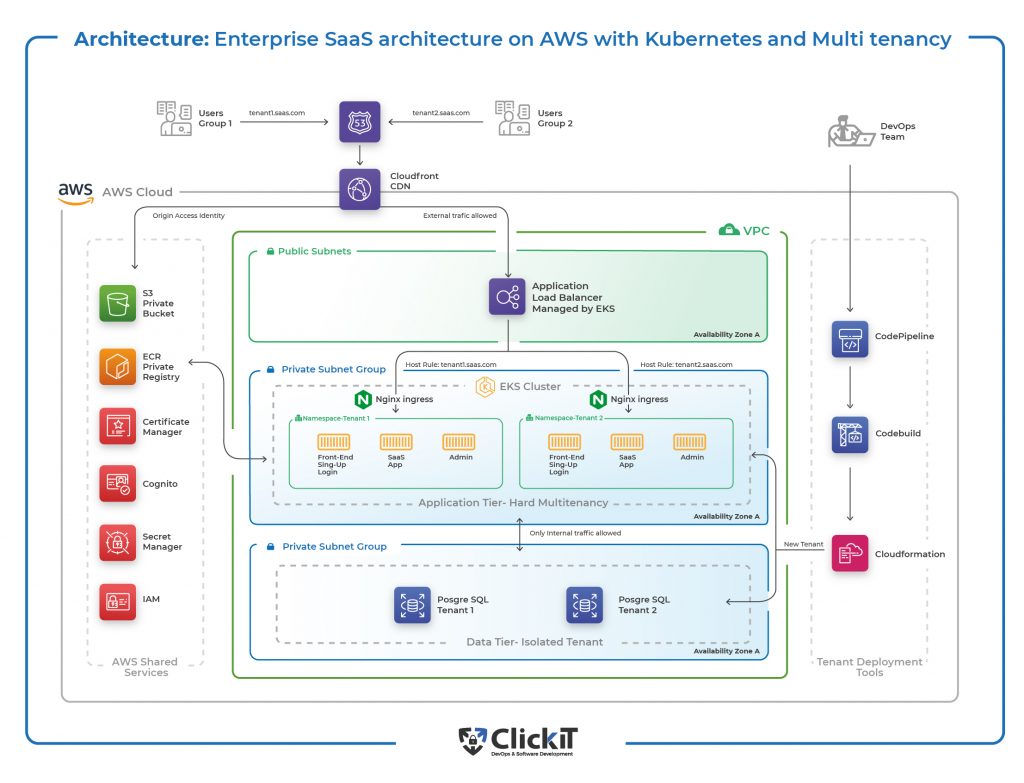
As you can see, we’re separating a lot of stuff into their own services. Container Registry, Certificate Managers, Secret Managers, IAM, different subnet groups for different services, and many different environments are all orchestrated by CloudFormation (as an example).
There’s no way a single person should maintain such an infrastructure; there are just too many things to keep in mind, and your daily to-do list will only grow longer. As the scale and complexity of your operations grow, having specialized teams for different aspects of DevOps becomes essential.
At this point you should consider splitting up your Infrastructure into different teams:
- Delivery Team: Responsible for CI/CD pipelines, they ensure that software is tested, built, and deployed efficiently and reliably.
- Tooling Team: Focuses on providing the internal tools and systems needed for development, testing, and operations. This includes everything from internal dashboards to log management systems to code review tooling.
- Monitoring Team: Implements monitoring solutions like Prometheus, Grafana, or Datadog to track application performance and health. Cross-Team alerts, on-call processes.
- Infrastructure Team: Manages the underlying servers, cloud services, and network infrastructure. They ensure that the infrastructure is scalable, reliable, and secure — complex TerraForm, Ansible, CloudFormation setups. They focus on the Infrastructure as Code. They have their own repositories where they develop the platform code that provisions the resources necessary to run your application.
- Security Team: Responsible for the penetration tests, certificates, key rotations, IAM Access.
- Compliance Team: Making sure the legal and the IT work smoothly together. This often involves audit trails, access controls, and regular security assessments.
In summary, the transition to enterprise level involves building teams with people smarter than you, who can tell you better than I can how to properly set up your infrastructure. It’s no longer possible for you to do any hands-on work here. As a CTO, your role is to guide this transition, ensuring that your infrastructure and teams are not just equipped for today's challenges but are also prepared for tomorrow's opportunities.
So TL;DR;
- When you’re starting out — there is no need to go for a fancy solution that is ready to serve a million concurrent users right away.
- DevOps is a luxury problem.
- Once you’ve grown to have such problems, you can start investing resources into more robust and more complicated deployment and server architecture.
- Enterprise is about assembling smarter people than you and splitting the infrastructure into sub-divisions.
Have fun building!
Other Newsletter Issues:
Worried your codebase might be full of AI slop?
I've been reviewing code for 15 years. Let me take a look at yours and tell you honestly what's built to last and what isn't.
Learn about the AI Audit →No-Bullshit CTO Guide
268 pages of practical advice for CTOs and tech leads. Everything I know about building teams, scaling technology, and being a good technical founder — compiled into a printable PDF.
Get the guide →
10 Comments
Totally agree. instead of jumping straight to Kubernetes and microservices because it’s the ‘cool’ thing to do, how about we focus on making sure the basics are solid? You know, like actually having a product that works and scales efficiently on simpler architectures. The worst startup CTO who plays around with technology too much.
Well, it’s heartening to see that the basics of scaling a tech stack haven’t changed in the last fourty years, even if the enthusiasm for over-engineering solutions seems to have reached new heights. we all learn best from our own mistakes.
Brings back memories. While I chuckle at the thought of CTRL+Z version control, I can’t help but admire the hustle, also to anyone else who wants to try it out: don’t do it, it might’ve been fun in 2007, but definitely not now. scaling up means saying goodbye to the wild west and today none of the startups can allow themselves to have CTRL+Z version control, even those with indie founders.
Your evolution from solo dev to CTO is inspiring, any more stories to share like the ones at the start of the article? would be cool to read
Starting simple and growing your tech stack as needed is the way to go. It’s all about adapting to what your product and team need over time. No need to complicate things from the start. Keep it clear and focus on making something users love. Skipping the tech maze early on saves resources and keeps you focused on the real goal. Plus, learning from what works (and what doesn’t) as you scale is invaluable. Keep it lean and mean, folks.
I would tend to agree on most points – startups should definitely keep the Ops light at the start of their journey.
The only thing that stood out to me was leaving containerization for quite late on. Maybe it’s because I am just very used to working with containers at this point, but I don’t see many downsides for using them from day 1 – they standardize the application lifecycle wonderfully and one only trades very little in terms of setup for that luxury.
As someone who has been through the evolution of tech stacks, I can say that starting simple and evolving based on needs is key. It’s refreshing to see a practical approach highlighted rather than just following the trend of over-engineering from the get-go. Growing a startup involves a lot of learning, trial, and error, but in the end, it’s all about providing value to the users. So, kudos to the author for sharing their experiences and insights in a relatable way.
Back in my early coding days, I did some over-engineering, thinking it would future-proof my project. Boy, was I wrong. Hours sunk into configuring Docker compositions and Kubernetes clusters for a user base that was practically non-existent. It was fun to scale the architecture, but I had zero traction. It was a classic case of putting the tech cart before the horse, without real demand driving those decisions. I did learn quite a bit of tech stuff.
When I first started playing around with my own projects, my setup was basic, just a bunch of scripts that somehow managed to work. I remember spending nights trying to figure out FTP uploads and feeling like a winner when my code finally ran on the server without errors. Moving from that to Docker felt like magic that somehow improved my entire process. Looking back, it’s wild how starting with those simple setups put me in the position to appreciate the complexity of modern DevOps practices.
Starting with a lean stack and gradually adding complexity as my project grew helped me stay focused and avoid getting bogged down with unnecessary tech.